

A2TTS-Telugu Speaker Adaptive TTS (Text-to-Speech)-v0.5
- Kasturi Murthy

- Sep 14
- 4 min read
In this blog post, I discuss my preliminary experiences with a speaker-adaptive text-to-speech (TTS) system aimed at producing high-quality, natural speech in the low-resource Indian language, Telugu [1]. As I am proficient in reading and writing Telugu (despite my writing skills having declined since completing my class 12), I decided to explore this TTS system.
AIKosh is an innovative initiative by the Government of India, aimed at democratizing access to artificial intelligence resources nationwide. Developed by the National e-Governance Division, AIKosh serves as a unified digital platform that consolidates datasets, AI models, computational tools, and sector-specific use cases to empower researchers, startups, and innovators.
This short blog post will discuss my preliminary experiments carried out with this system. To access the model, you need to register and obtain permission to download it from AIKosh. Once I received approval from the model contributors, likely linked to IIT, Mumbai [1], I downloaded the model and developed a Python Jupyter notebook using the available TTS model features. Logging into AIKosh is relatively straightforward, and although there are several methods, I opted for the Digilocker route.
A2TTS: TTS for Low Resource Indian Languages
The model outlined in the publication employs attention mechanisms and diffusion-based mel-spectrogram refinement for synthesizing multi-speaker text-to-speech. The document details that Grad-TTS forms the core of the system, integrating diffusion-based text-to-speech architecture with speaker conditioning techniques.
By incorporating speaker conditioning methods from UniSpeech, the model improves the preservation of speaker identity and prosody in the generated speech.
Grad-TTS [3,4] retains components like text encoding, duration prediction, and diffusion-based mel spectrogram synthesis, but enhances them with cross-attention mechanisms for better alignment of linguistic and speaker features, resulting in more natural speech synthesis.
To prevent overfitting, the reference mel spectrogram is intentionally unrelated to the input text, enabling the model to concentrate on speaker-specific timing and intonation patterns.
Speaker identity is meticulously addressed through speaker conditioning strategies, including the application of speaker embeddings and classifier-free guidance during inference to boost expressiveness and ensure speaker consistency.
What is GradTTS?
Grad-TTS is a cutting-edge text-to-speech (TTS) model that uses diffusion probabilistic modeling to generate high-quality speech from text. Developed by researchers including Vadim Popov and colleagues, it was introduced in a paper accepted to ICML 2021 [2], [3,4].
Key Features
Diffusion-based generation: Instead of directly predicting speech features, Grad-TTS gradually transforms random noise into a mel-spectrogram using a score-based decoder. This process is inspired by denoising diffusion probabilistic models.
Monotonic Alignment Search: It aligns text input with audio features in a stable and efficient way, improving the quality and consistency of synthesized speech.
Flexible inference: Users can control the trade-off between audio quality and generation speed, making it adaptable for different applications.
Multilingual and multispeaker support: It can be extended to handle multiple languages and voices, especially when paired with models like HiFi-GAN for vocoding [3,4]
My Experiment with Telugu - TTS
I developed this Jupyter notebook based on the code I was permitted to download. While the original model included a Gradio-based user interface for interactive demos, I found that working within Jupyter offered greater flexibility and control for my workflow.
This notebook demonstrates a modular pipeline for zero-shot voice cloning, integrating the following components:
GradTTS: A diffusion-based text-to-speech synthesis model
HiFi-GAN: A neural vocoder for high-fidelity waveform generation
SpeakerEncoder: Used to extract speaker embeddings from reference audio—my own voice served as the input here
Gradio (optional): For web-based interaction, though I opted for notebook-based execution
For the Telugu text inputs, I selected verses from the poems of Yogi Vemana, a celebrated philosopher-poet known for his succinct, thought-provoking couplets. These short poems, rich in moral insight and social commentary, served as ideal linguistic material for testing the TTS model.
Telugu Text Inputs: 'ఉప్పు కప్పురంబు నొక్కపోలికెను౦డు జూడ జూడ రుచుల జూడ వేరు పురుషులందు పుణ్య పురుషులూ వెరయా' (* I beg your pardon if there are mistakes in this Telugu Text)
Voice Input: My voice in .wav format
Input wave form for Encoder:
SpeakerEncoder: Used to extract speaker embeddings from reference audio—my own voice served as the input here
Outputs:
Text to Speech generated audio
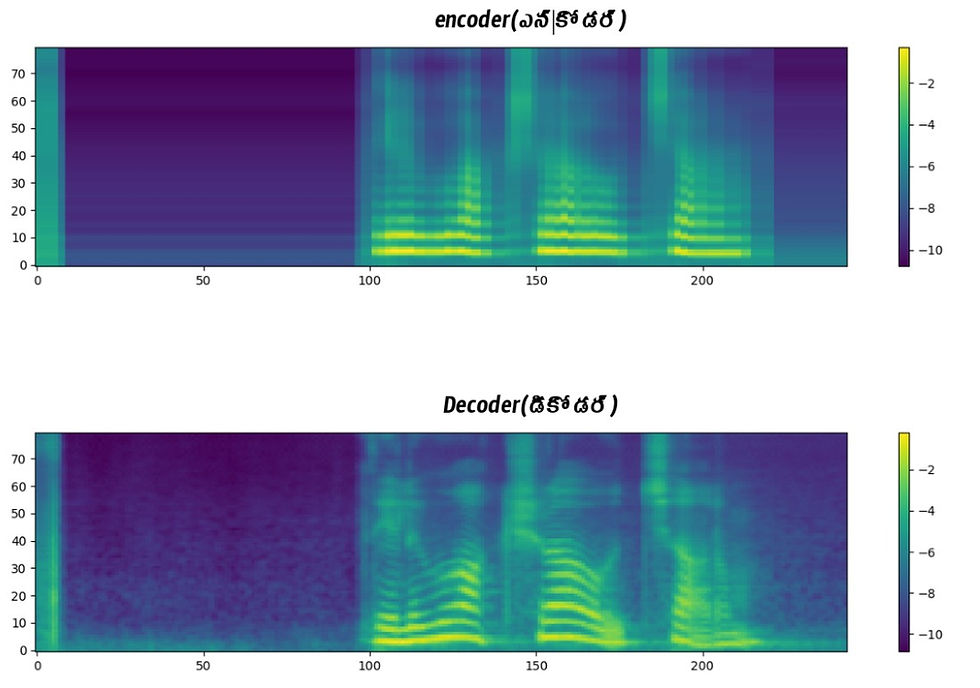
Encoder (also known as the reference mel spectrogram) and Decoder Mel Spectrum Waveforms. The encoder in this context processes the input phoneme sequence, typically representing a sequence of phonemes, to generate dense vector representations that capture contextual relationships among phonemes. These dense embeddings, obtained from the input text, serve as core linguistic features used in downstream modules like duration prediction and mel spectrogram generation. The encoder's role is crucial in extracting and encoding phonetic and linguistic structures to enable high-quality speech synthesis with accurate prosody and speaker-specific characteristics. The decoder in the described model architecture takes the attention output from the encoder and refines an initial mel spectrogram representation through a de-noising diffusion probabilistic model (DDPM). It iteratively refines the spectrogram through a reverse diffusion process, enhancing the quality of the mel spectrogram for speech synthesis. Additionally, the decoder is conditioned on speaker identity using speaker embeddings from a pre-trained speaker encoder, ensuring speaker consistency and expressive speech generation. The decoder's role is crucial in generating high-quality mel spectrograms that capture both linguistic content and speaker characteristics for natural-sounding speech synthesis. So, the decoder mel spectrogram captures the refined and improved spectrogram representation that incorporates linguistic content and speaker characteristics for natural-sounding speech synthesis

Attention Waveform. Attention refers to a crucial component of the model's architecture used to capture speaker-specific timing and intonation patterns in the speech synthesis process. The attention output is generated based on the reference mel spectrogram, queries, and serves as both keys and values within the system. This mechanism allows the model to focus on capturing distinct speaker characteristics and produce speaker-adaptive durations for more expressive and natural-sounding speech synthesis.
Conclusions
It appears that Grad-TTS is effective, but it might require a phoneme sequence more specific to the Telugu language. A more precise input phoneme sequence might be necessary for training this model. This is just an initial assessment, and I could be mistaken!
References
Interesting to see this